
The shortest path problem is one of the central research problem in the algorithmic research. The main setup for this problem is to find distances from given start vertex to all other nodes in the graph. Probably, the most important results here are Dijkstra and Belmann-Ford algorithms -- both from around 1960. Dijkstra considered directed graphs with non-negative weight edges. His algorithm can be implemented to run in O(m+n log n) time using Fibonacci heaps. On the other hand, Belman-Ford solved the directed problem with negative weights in O(nm) time. You might note that for non-negative weights the shortest paths problem in undirected graph can be solved via reduction to directed case, so Dijkstra is applicable here as well. Although there exists a faster linear time solution for undirected graph with integral weights that is due to Thorup [1]. Similarly, for the case of directed graphs with negative weights there has been some progress. First, in 80s two scaling algorithms working in [2] and
[3] have been given. In these algorithms one assumes that edge weights are integral with absolute value bounded by W. Second, in 2005 two algebraic algorithms working in
time have been presented [4,5], where
is matrix multiplication exponent. There is even more work in between these results that I did not mention, and much more papers studying all pairs shortest paths, or special cases like planar graphs. However, we have not mentioned the undirected shortest path problem on graphs with negative weight edges yet... Is this problem actually solvable in polynomial time? Yet it is, this has been shown by Edmonds in '67 via a reduction to matchings [6]. These notes are probably lost... maybe not lost but probably hard to access. Anyway the reduction is given in Chapter 12.7 of [7]. Let us recall it We will essentially show that in order to find the distance from fixed source s to fixed sink t one needs to solve minimum weight perfect matching problem once.
Let G=(V,E) be an undirected graph, let be the edge weight function and let
be the set of edges with negative weights. We will define a graph
that models paths in G by almost perfect matchings. We define the split graph
with the weight function
in the following way
An undirected graph G and its graph are shown on the figure below.
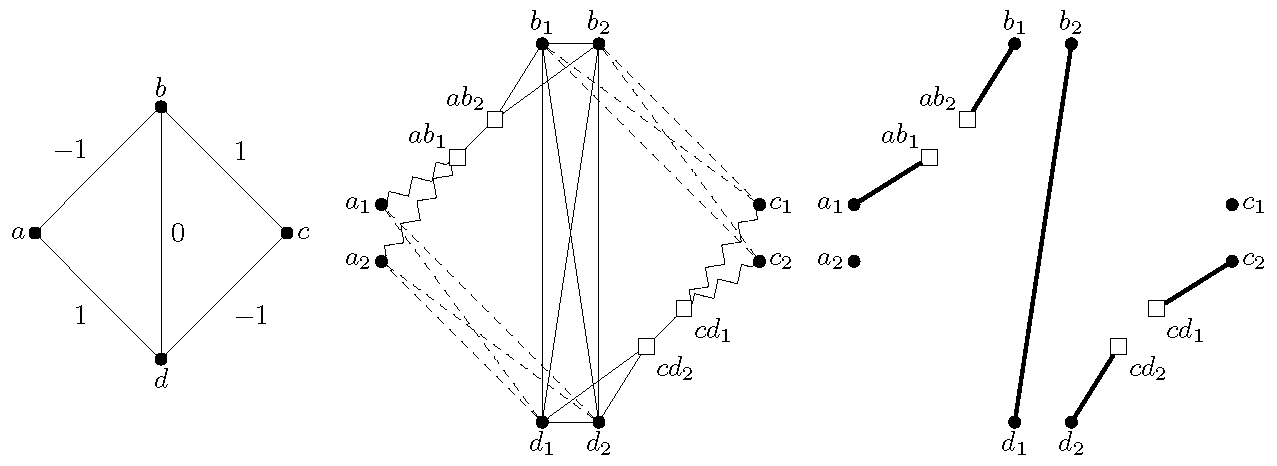
In zigzag edges weigh -1, dashed edges weigh 1 and the remaining edges weigh 0. Vertices corresponding to negative edges of G are white squares. The far right shows a matching
of weight -2, which corresponds to a shortest path between a and c. Note how a length-two path in G, say a,b,c with w(ab)?0>w(bc) and e=bc, corresponds to
a matching in such as
, having the same total weight.
An important property is that we can assume . This follows since we can assume
, as otherwise the set of negative edges contains a cycle.
Let us consider minimum weight perfect matchings in , then we can observe the following.
Lemma 1.
Let , let M be the minimum weight perfect matching, and let
be the minimum weight almost perfect matching in
that does not match
. If G does not contain negative weight cycles then
and the shortest path weight from u to v in G is equal to
.
Hence, in order to solve the same problem as Belman and Ford did, i.e., to compute the distances from given source to all other nodes we need to run some matching algorithm O(n) times. This does not seem to be right. Even using fast implementation of Edmonds weighted matching algorithm [8] one needs time, whereas Belman-Ford algorithm works just in O(nm) time. There seem to be something lost here, or at least overlooked through the years. Searching through the literature one can find partial answers that shed some light on the structure of such shortest paths. Sebö has characterized the structure of single-source shortest paths in undirected graphs, first for graphs with ±1 edge weights [9] and then extending to general weights by reduction [10]. Equation (4.2) of [9] (for ±1-weights, plus its version achieved by reduction for arbitrary weights) characterizes the shortest paths from a fixed source in terms of how they enter and leave "level sets" determined by the distance function. However, this is just a partial answer as it does not show how the shortest path "tree" looks like, or does not give an efficient way to compute it. We write "tree", because one might observe that the shortest paths do not necessary form a tree -- as shown on the figure below.
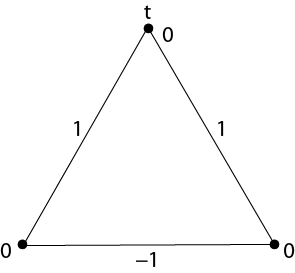
So how do shortest paths look like? Is there some notion of shortest path tree here? If yes then is this shortest path tree of O(n) size? In our recent paper with Hal Gabow, that is available on arXiv, we give answers to these question. For undirected shortest paths we get a somewhat simple definition of a generalized shortest-path tree -- see Section 6.1 of our paper. (It seems to us that such a definition may have been overlooked due to reliance on reductions.) The generalized shortest-path tree is a combination of the standard shortest-path tree and the matching blossom tree. This is not so astonishing if you recall the above reduction to matchings in general graphs. Examining the blossom structure of the resulting graph enables us to define our generalized shortest-path tree that, like the standard shortest-path tree for directed graphs, specifies a shortest path to every vertex from a chosen source. We give a complete derivation of the existence of this shortest-path structure, as well as an algebraic algorithm to construct it in time . We also construct the structure with combinatoric algorithms, in time
or
. Hence, this settles the problem, as these bounds are all within logarithmic factors of the best-known bounds for constructing the directed shortest-path tree with negative weights.
[1] M. Thorup, Undirected single-source shortest paths with positive integer weights in linear time, JACM, 46(3):362--394, 1999.
[2] H. N. Gabow and R. E. Tarjan, Faster scaling algorithms for network problems, SIAM Journal on Computing, 18(5):1013--1036, 1989.
[3] A. V. Goldberg, Scaling algorithms for the shortest paths problem, SODA '93.
[4] R. Yuster and U. Zwick, Answering distance queries in directed graphs using fast matrix multiplication, FOCS'05.
[5] P. Sankowski, Shortest Paths in Matrix Multiplication Time, ESA'05.
[6] J. Edmonds, An introduction to matching. Mimeographed notes, Engineering Summer Conference, U. Michigan, Ann Arbor, MI, 1967.
[7] R. K. Ahuja, T. L. Magnanti and J.B. Orlin, Network Flows: Theory, Algorithms, and Applications, Prentice Hall, 1993.
[8] H. N. Gabow, Data Structures for Weighted Matching and Nearest Common Ancestors with Linking, SODA'90.
[9] A. Sebö, Undirected distances and the postman-structure of graphs, J. Combin. Theory Ser. B, 49(1):10--39, 1990.
[10] A. Sebö, Potentials in Undirected Graphs and Planar Multiflows, SIAM J. Comput., 26(2):582--603, 1997.









